逐語的一致 / Verbatim Match
要約
他者のテキストを一字一句そのままコピーしている状態。剽窃の中で最もリスクが高く、コピペチェックツールで即座に検出される。引用符と出典なしの逐語的一致は著作権侵害に直結する
逐語的一致とは、他者のテキストを一字一句そのままコピーしている状態のことです。英語では Verbatim Match と呼ばれ、剽窃(プレイジャリズム)の類型の中で最も重大な違反とされています。引用符や出典の表記がない逐語的一致は、意図的か否かに関わらず著作権侵害に直結します。
コピペチェックツールの一致率は、主にこの逐語的一致を検出する指標です。一致率が高い場合、記事内に逐語的一致の箇所が多く含まれていることを意味します。AI 生成コンテンツでも、学習データのフレーズがそのまま出力されるケースがあり、公開前のチェックが欠かせません。
なぜ逐語的一致が問題なのか
逐語的一致は、他の剽窃類型と比較して最もリスクが高い理由を解説します。
著作権法上の問題
日本の著作権法では、著作物の無断複製は複製権(第21条)の侵害に当たります。逐語的一致は原文をそのまま複製した状態であるため、侵害の立証が容易です。裁判所が著作権侵害を判断する際、逐語的一致は「依拠性」(元の著作物を参照したこと)と「類似性」の両方を強く推定させる根拠となります。
SEO への影響
Google は重複コンテンツを検索品質の低下要因として処理します。逐語的一致が多い記事はコピーコンテンツとして扱われ、検索順位の低下やインデックスからの除外対象になります。意図的なコピーと判断された場合は手動アクション(スパム判定)を受ける可能性もあります。
信頼性の低下
コンテンツの逐語的一致が発覚すると、サイト全体の信頼性が損なわれます。E-E-A-T の「信頼性(Trustworthiness)」に直接影響し、ユーザーからの信頼を失うだけでなく、取引先やパートナー企業からの評判にも影響します。
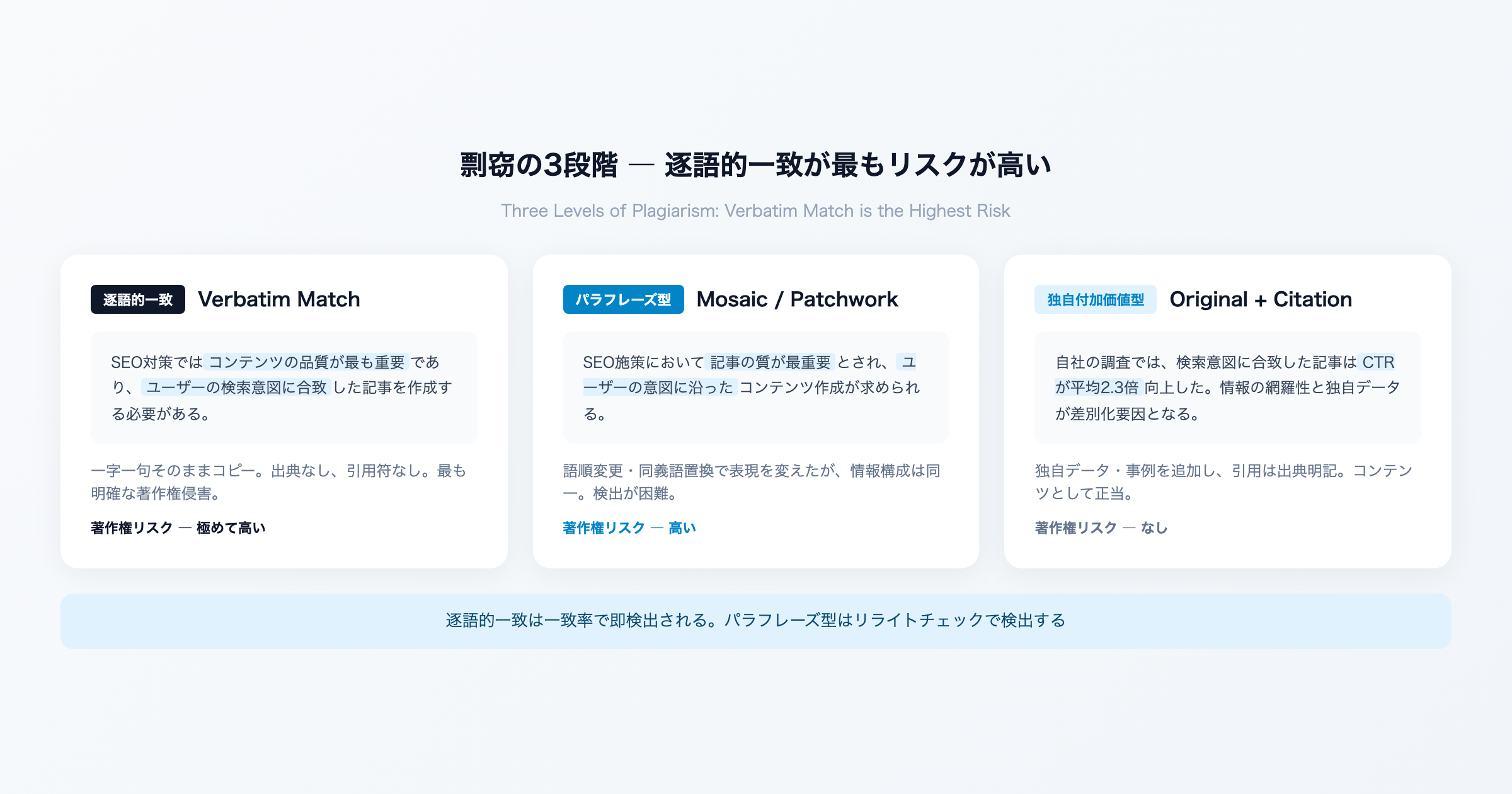
剽窃の3段階と逐語的一致の位置づけ
剽窃には重大度に応じた段階があり、逐語的一致は最も重大な類型です。
| 類型 | 定義 | 検出の容易さ | 著作権リスク |
|---|---|---|---|
| 逐語的一致 | 原文を一字一句そのままコピー | 容易(一致率で即検出) | 極めて高い |
| モザイク型剽窃 | 語順変更・同義語置換で表現を改変 | 中程度(リライトチェックで検出) | 高い |
| アイデアの盗用 | 情報構成・論理展開をそのまま流用 | 困難(構造分析が必要) | 状況による |
逐語的一致はコピペチェックで容易に検出されるため、意図的に行うケースは少なくなっています。しかし、AI 生成コンテンツの普及により、意図せず逐語的一致が発生するケースが増えています。
「少量のコピペなら問題ない」という認識は誤りです。たとえ 1 文であっても、引用符と出典なしの逐語的一致は著作権侵害のリスクがあります。分量ではなく、引用の要件を満たしているかどうかが判断基準です。
逐語的一致と引用の違い
逐語的一致がすべて違法というわけではありません。著作権法第32条に基づく適切な引用であれば、原文をそのまま使用しても合法です。
引用の要件
著作権法上の引用として認められるには、以下の要件を全て満たす必要があります。
| 要件 | 具体的な内容 | 不備の場合 |
|---|---|---|
| 主従関係 | 自分の文章が「主」、引用部分が「従」 | 引用量が多すぎると転載とみなされる |
| 明瞭区分 | 引用符(「」、blockquote)で引用部分を明示 | 自分の文章と区別できず剽窃とみなされる |
| 出典表記 | 著者名・書名・URL などを明記 | 出典表記の不備で引用として不成立 |
| 必要性 | 引用が議論や説明に必要であること | 不必要な引用は引用の要件を満たさない |
| 改変禁止 | 原文を改変しないこと(同一性保持権) | 要約する場合は引用ではなく参考として扱う |
引用の正しいルールでは、これらの要件を実務的な観点から詳しく解説しています。
引用と逐語的一致の境界線
同じテキストの完全一致であっても、引用の要件を満たしていれば合法、満たしていなければ剽窃です。つまり、逐語的一致かどうかを判断するのは「テキストが一致しているか」ではなく「引用の形式を備えているか」です。
コピペチェックツールが検出する一致率には、適切に処理された引用も含まれます。一致率が高い場合は、引用箇所と非引用箇所を区別して確認してください。引用として適切な箇所は一致率が高くても問題ありません。
AI 生成コンテンツと逐語的一致
AI を活用した記事制作で発生する逐語的一致のリスクと対策を解説します。
逐語的一致が発生するケース
AI(LLM)が逐語的一致を含む文章を生成するケースには、以下のパターンがあります。
| パターン | 具体例 | 発生頻度 |
|---|---|---|
| 定義文の再現 | 「SEO とは Search Engine Optimization の略で...」 | 高い |
| 法律条文の引用 | 著作権法の条文がそのまま出力される | 中程度 |
| 統計データの記述 | 公開データの記述がそのまま再現される | 中程度 |
| 固有名詞の列挙 | ツール名やサービス名の説明文 | 低い |
特に定義文や説明文は、表現のバリエーションが限られるため、学習データの原文がほぼそのまま出力される可能性があります。AI コンテンツの剽窃チェックでも、この問題について詳しく解説しています。
対策
AI 生成コンテンツの逐語的一致を防ぐための実践的な対策を示します。
- 公開前にコピペチェックツールで一致率を確認する
- 一致率が高い箇所を特定し、独自の表現で書き直す
- 定義文や説明文には自社の視点や具体例を追加する
- 統計データを引用する場合は出典を明記し、引用の形式で処理する
逐語的一致への対処法
逐語的一致が検出された場合の具体的な対処法を、状況別に整理します。
引用として処理する場合
逐語的一致の箇所が引用として適切な場合は、引用の形式を整えます。
- 引用符(「」)または blockquote タグで引用部分を囲む
- 出典(著者名、書名、URL、アクセス日)を明記する
- 引用部分が記事全体の「従」であることを確認する
- 引用が議論や説明に必要であることを確認する
独自表現に書き直す場合
引用ではなく自分の言葉で表現すべき箇所は、以下のアプローチで書き直します。
- 独自のデータや事例を追加して情報の付加価値を高める
- 文の構造を変更する(能動態 ↔ 受動態、文の分割・統合)
- 自社の経験や知見に基づく独自の解釈を加える
- 表やリスト形式に再構成して情報を整理する
コピペチェック完全ガイドでは、コピペ率を改善する具体的なテクニックを紹介しています。
spotyou での活用
spotyou のコンプライアンスチェック機能は、一致率の算出に加えて逐語的一致の箇所をハイライト表示します。逐語的一致が検出された箇所ごとに「引用として処理する」「独自表現に書き直す」の選択肢が提示され、修正提案も表示されます。
記事の生成からコピペチェック、逐語的一致の修正まで一つのワークフローで完結するため、無料 vs 有料コピペチェックツール比較で指摘されている外部ツール連携の手間が発生しません。
まとめ
- 逐語的一致は他者のテキストを一字一句そのままコピーしている状態であり、剽窃の中で最もリスクが高い
- 引用符と出典なしの逐語的一致は著作権侵害に直結する
- 著作権法第32条の要件を満たした引用であれば、逐語的一致であっても合法
- AI 生成コンテンツでは定義文や説明文で意図しない逐語的一致が発生しやすい
- 対処法は「引用として正しく処理する」か「独自表現で書き直す」の2択
よくある質問
逐語的一致とは何ですか?
他者のテキストを一字一句そのままコピーしている状態のことです。英語ではVerbatim Matchと呼ばれます。引用符や出典なしの逐語的一致は剽窃(プレイジャリズム)の中で最も重大な違反とされ、著作権侵害に直結します。
逐語的一致とモザイク型剽窃の違いは?
逐語的一致は原文をそのままコピーする行為です。モザイク型剽窃は原文の一部を言い換えたり語順を変えたりしながら、情報の構成や論理展開をそのまま流用する行為です。逐語的一致はコピペチェックで容易に検出されますが、モザイク型剽窃はリライトチェックでないと見逃される場合があります。
引用は逐語的一致に該当しますか?
いいえ。著作権法第32条の要件(主従関係、明瞭区分、出典明記、必要最小限)を満たした引用は、逐語的一致であっても合法です。引用符(「」やblockquote)で区分し、出典を明記していれば剽窃には当たりません。
AI生成コンテンツで逐語的一致が発生する理由は?
AIは学習データに含まれるフレーズを再構成して文章を生成しますが、短い定型表現や専門用語の定義文など、バリエーションが限られる箇所では学習データの原文がそのまま出力されることがあります。公開前のコピペチェックで検出できます。
逐語的一致が検出された場合の対処法は?
引用として適切に処理するか(引用符と出典の追加)、独自の表現で書き直します。引用する場合は主従関係(自分の文章が主、引用が従)を保つ必要があります。大量の逐語的一致がある場合は記事全体の書き直しが推奨されます。