AI生成記事のコピペ・剽窃、どこからがアウト?
この記事のポイント
AI 記事の剽窃は「逐語的一致」「パラフレーズ」「モザイク型」の 3 パターンに分かれ、コピペ率が低くても構造的類似で著作権侵害になり得ます。公開前に 5 ステップのチェックフローを回し、事実情報と独自見解を明確に分離することがリスク回避の鍵です。
剽窃チェックとは、作成した文章が既存の著作物と内容的に重複・類似していないかを検証する作業のことです。従来のコピペチェックが「文字列の一致」を検出するのに対し、剽窃チェックはパラフレーズや構造的な類似まで含めた、より広い範囲の重複を対象とします。AI で記事を生成する時代には、ツールが検出する「コピペ率」だけでなく、学習データからの無意識な再現や構造的な盗用まで視野に入れた剽窃チェックが不可欠です。
AI 生成記事の剽窃とは? 従来のコピペとの違い
AI を使って記事を作成する企業が増える中、「コピペチェックはやっている」という声は多く聞かれます。しかし、AI 生成記事における剽窃のリスクは、従来のコピペとは性質が異なります。コピペチェックツールで一致率が低くても、実質的な剽窃に該当するケースが存在するのです。
「コピペ」と「剽窃」は何が違うのか
コピペ(コピー・アンド・ペースト)は、他者の文章をそのまま複製する行為です。文字列が完全に一致するため、ツールで容易に検出できます。
一方、剽窃はより広い概念です。文字列が一致しなくても、他者のアイデア、論理構成、分析の切り口を自分のものとして提示すれば剽窃に該当します。学術論文の世界では古くから厳しく取り締まられてきましたが、ウェブコンテンツの領域では認識がまだ追いついていません。
AI 生成記事においては、この「剽窃」の定義を正しく理解することがリスク管理の出発点になります。
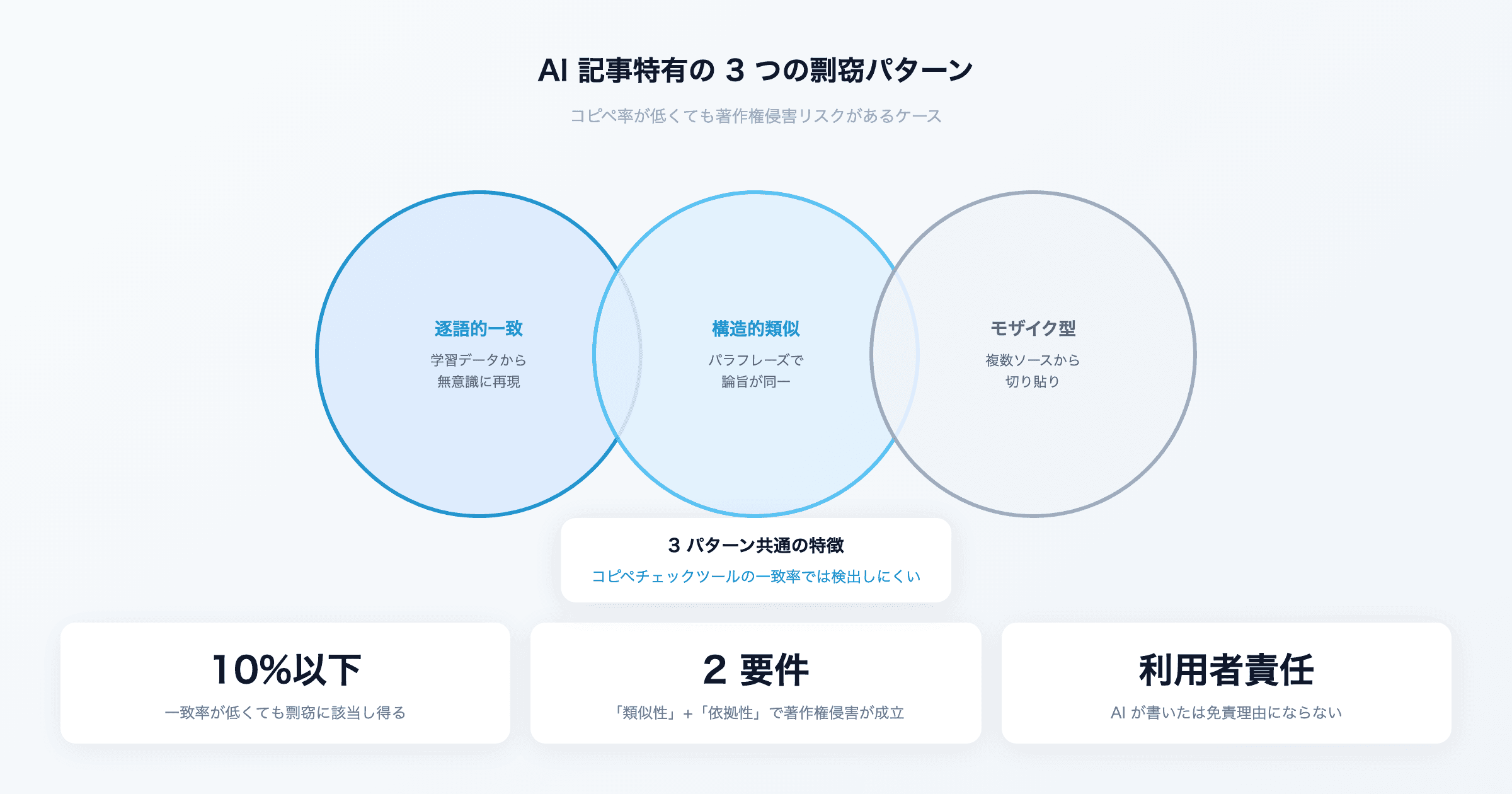
AI 記事特有の 3 つの剽窃パターン
AI が生成する記事には、人間が手動でコピペする場合とは異なる、特有の剽窃パターンがあります。
パターン 1 は、学習データからの無意識な再現です。AI は膨大なテキストデータを学習しており、特定のフレーズや表現を「記憶」しています。プロンプトに応じて、学習データ中の文章をほぼそのまま出力してしまうことがあります。利用者は元ネタの存在すら知らないまま、逐語的に一致した文章を公開してしまうリスクがあるのです。
パターン 2 は、パラフレーズによる構造的類似です。AI は同じテーマで質問されると、学習データの中で支配的だった論理構成や説明の流れを再現しやすい傾向があります。語彙は変わっていても、見出しの順序、主張の展開、結論の導き方が特定のソースと酷似するケースです。
パターン 3 は、複数ソースの「パッチワーク」です。モザイク型剽窃とも呼ばれ、AI が複数の情報源からフレーズや論旨を切り貼りして一つの文章を構成するパターンです。個々のフレーズは短いため一致率は低く出ますが、全体として他者の著作物の寄せ集めになっています。
この 3 つのパターンに共通するのは、コピペチェックツールの一致率では検出しにくいという点です。一致率が 10% 以下でも、これらのパターンに該当すれば著作権侵害のリスクがあります。
どこからが「アウト」なのか? 法的な判断基準
「剽窃は問題」と言われても、具体的にどこからが法的にアウトなのかが分からなければ対策の打ちようがありません。ここでは、著作権法の判断基準と公的なガイドラインを整理します。
著作権侵害の 2 要件: 「類似性」と「依拠性」
著作権侵害が成立するには、「類似性」と「依拠性」の 2 つの要件が必要とされています。
類似性とは、問題の文章が既存の著作物と表現上似ているかどうかです。アイデアそのものは著作権で保護されませんが、アイデアの表現方法が類似していれば該当する可能性があります。
依拠性とは、既存の著作物に基づいて作成されたかどうかです。偶然の一致であれば著作権侵害にはなりません。しかし、AI の場合はここに特殊な問題が生じます。
文化庁ガイドライン(2024 年 3 月)が示す考え方
2024 年 3 月に文化庁が公表した「AI と著作権に関する考え方」では、AI 生成物と既存著作物の関係について重要な見解が示されました。
このガイドラインの要点は、AI が学習データに含まれる著作物と類似した出力を生成した場合、「類似性」と「依拠性」の両方が認められ得るという考え方です。AI が学習したデータに基づいて生成しているという事実そのものが、依拠性を推認させる根拠になり得ます。
つまり、「AI が勝手にやったこと」という抗弁は通用しにくく、AI を利用して生成・公開した側に責任が発生する構造になっています。
AI 利用者が知らなくても「依拠性あり」と判断されるケース
従来の著作権侵害訴訟では、「元の著作物にアクセスしたことがない」という反論が有効な場面もありました。しかし、AI 生成記事ではこの反論が成り立ちにくくなります。
AI は膨大なテキストデータを学習しています。利用者自身が元の著作物を読んだことがなくても、AI が学習データとして取り込んでいれば、その出力は「依拠している」と判断される可能性があります。利用者の認識に関わらず、AI というツールを介して既存著作物への依拠が成立し得るという点が、AI 時代の著作権問題の核心です。
Google の見解: AI 生成コンテンツは品質と独自性で評価
法的リスクに加えて、検索エンジンの評価という実務上のリスクもあります。
Google は「AI 生成かどうか」ではなく「コンテンツの品質と独自性」で評価するという方針を明確にしています。つまり、AI で書いたこと自体がペナルティの対象になるわけではありませんが、独自の価値がないコンテンツ、他サイトと実質的に同じ内容のコンテンツは低品質と判断されます。
E-E-A-T(経験・専門性・権威性・信頼性)の観点から、独自の経験や分析が含まれていないコンテンツは検索順位の低下につながります。剽窃チェックは、法的リスクの回避だけでなく、検索パフォーマンスの維持にも直結するのです。
「コピペ率○%以下なら OK」は本当か? 数値基準の落とし穴
「コピペ率を 30% 以下に抑えれば大丈夫」という基準を運用ルールにしている企業は少なくありません。しかし、この数値基準には大きな落とし穴があります。
一致率が低くても剽窃になるケース、高くても問題ないケース
一致率が低くても剽窃になるケースの代表例が、パラフレーズによる構造的類似です。元の記事と見出し構成がほぼ同一で、主張の展開順序も同じ、使われている具体例も同じ。しかし語彙を入れ替えているため一致率は 5% しかない。このような記事は、ツール上は「問題なし」ですが、著作権法上は「類似性あり」と判断される可能性があります。
逆に、一致率が高くても問題ないケースもあります。
| 一致率が高くなるケース | 問題の有無 |
|---|---|
| 法令の条文を引用している | 適切な引用であれば問題なし |
| 固有名詞・専門用語が多い(医療、法律、IT 分野) | 表現を変えると正確性が損なわれるため問題なし |
| 適切な出典を明示した引用 | 引用の要件を満たしていれば問題なし |
| 自社の過去記事との重複 | 権利者が同一であれば問題なし |
つまり、一致率の数字だけでは「アウトかセーフか」を判断できません。一致の中身を確認する工程が必ず必要です。
AI 記事で一致率が高くなりやすい理由
AI 生成記事は、人間が手書きした記事と比較してコピペチェックの一致率が高くなりやすい傾向があります。その理由は主に 3 つです。
1 つ目は、AI が「定型表現」を多用することです。AI は学習データの中で頻出するフレーズを好んで使うため、他の AI 生成記事や元となった学習データの表現と一致しやすくなります。
2 つ目は、同一テーマでの「収束」です。同じテーマについて複数の AI ユーザーが記事を生成すると、構成や表現が似通います。結果として、ウェブ上に類似した記事が増え、後から公開した記事の一致率が高く出ます。
3 つ目は、事実情報の記述が大部分を占めることです。AI は事実の記述を正確に書こうとするため、同じ事実を扱う記事との一致率が必然的に高くなります。独自の分析や体験談が少ない記事ほど、この傾向が顕著です。
公開前に実施すべき剽窃チェック 5 つのステップ
AI 生成記事を安全に公開するためには、ツールの一致率確認だけでは不十分です。以下の 5 ステップで体系的にチェックすることをお勧めします。
ステップ 1: コピペチェックツールで一致率を確認する
最初のステップは、コピペチェックツールによる一次スクリーニングです。文字列レベルの重複を検出し、明らかなコピーを除外します。一致率が極端に高い箇所(50% 以上)は、この段階で修正または削除の判断を行います。
ここで重要なのは、一致率の数字を「合否判定」ではなく「精査対象の選別」として使うことです。一致率が低ければ安全、高ければ危険、という単純な判断は避けてください。
ステップ 2: 一致箇所の「引用元」を目視で確認する
ツールが検出した一致箇所について、引用元のコンテンツを実際に目で確認します。確認すべきポイントは以下の通りです。
- 一致しているのは固有名詞や専門用語か、それとも文章表現そのものか
- 引用元は公共の情報源(法令、統計データ等)か、それとも特定の著者による創作物か
- 一致箇所の分量は全体に対してどの程度か
この工程を省くと、「ツールが問題ないと言ったから大丈夫」という思考停止に陥ります。
ステップ 3: 構造的類似(パラフレーズ剽窃)を確認する
ツールでは検出できない構造的な類似を確認するステップです。検索上位 3 ~ 5 記事の見出し構成と自社記事を見比べ、以下の点をチェックします。
- 見出しの順序や論理展開が特定の記事と酷似していないか
- 使用している具体例やデータが同一でないか
- 主張の根拠として同じ情報源だけに頼っていないか
AI 生成記事は、検索上位の記事と構成が似通いやすい傾向があります。意識的に独自の切り口を追加する必要があります。
ステップ 4: 事実情報と独自見解を明確に分離する
AI が生成した文章の中で、「一般的な事実の記述」と「独自の分析・見解」を明確に分けます。事実情報には出典を付し、独自見解の部分には自社の経験やデータに基づく根拠を追加します。
この分離が曖昧なまま公開すると、AI が学習データから借用した「それっぽい分析」が他サイトの論旨と酷似するリスクがあります。「この見解は誰のものか」を常に意識してください。
ステップ 5: 専門領域は追加チェックを行う
医療、法律、金融など専門性の高い領域の記事は、通常の剽窃チェックに加えて以下の追加チェックが必要です。
- 専門家によるファクトチェック(AI のハルシネーション対策)
- 業界固有の規制(薬機法、金融商品取引法等)への準拠確認
- 学術論文や公的機関の発表を引用している場合の出典の正確性確認
AI が自信を持って書いた専門的な記述が、実は不正確だったり、特定の論文の表現をそのまま再現していたりするケースは珍しくありません。
この 5 ステップを毎回手動で行うのは現実的ではありません。ステップ 1 のツールチェックとステップ 3 ~ 5 の品質確認を一つのワークフローにまとめることで、チェック漏れと作業負荷の両方を軽減できます。
海外の剽窃チェックツールの現状と日本語対応の壁
剽窃チェックの分野では、海外のツールが先行しています。しかし、日本語コンテンツに適用する際には大きな壁が存在します。
Originality.ai / Copyleaks の精度と機能
Originality.ai は、AI 生成コンテンツの検出と剽窃チェックを組み合わせたツールです。「この文章が AI で書かれたものかどうか」と「既存コンテンツとの重複があるかどうか」を同時にチェックできる点が特徴です。
Copyleaks は、学術機関や企業向けに多言語対応の剽窃検出サービスを提供しています。パラフレーズの検出機能も備えており、単純な文字列一致だけでなく構造的な類似も検出対象に含めています。
いずれも英語コンテンツに対しては高い精度を誇ります。しかし、日本語に対する精度は大きく異なります。
| 観点 | 英語での精度 | 日本語での精度 |
|---|---|---|
| 文字列の一致検出 | 高い | 中程度 |
| パラフレーズの検出 | 高い | 低い |
| AI 生成コンテンツの判定 | 高い | 低い |
| インデックスされた比較対象の量 | 膨大 | 限定的 |
日本語は英語と異なり、単語の区切りが明示されない膠着語です。形態素解析(単語の区切りと品詞の判定)の精度がチェック結果を大きく左右しますが、海外ツールの日本語形態素解析は英語圏のそれと比べて精度が低いのが現状です。
日本語で剽窃チェックからコンプライアンスチェックまで一貫して行う方法
海外ツールの日本語対応には限界がある。では、日本語コンテンツの剽窃チェックはどうすればよいのか。
現実的なアプローチは、コピペチェック(文字列の一致検出)とコンプライアンスチェック(法令準拠の確認)を一つのワークフローに統合することです。剽窃リスクは著作権の問題だけでなく、薬機法や景表法の違反リスクとも密接に関わります。これらを別々のツールで個別にチェックするのは非効率であり、チェック漏れの原因にもなります。
spotyou では、AI 記事の生成からコンプライアンスチェックまでを日本語で一貫して行えます。コピペチェックの結果を個別に確認し、著作権、薬機法、景表法の観点からリスクのある表現を指摘する機能を備えています。海外ツールのように英語のインターフェースで日本語コンテンツを扱う必要がなく、日本語の文脈を踏まえたチェックが可能です。
コピペチェックのツール比較と選び方では、各ツールの特徴と使い分けを詳しく解説しています。
まとめ: 「知らなかった」では済まされない時代の備え方
AI 生成記事の剽窃リスクは、従来のコピペチェックの延長線上にはありません。ツールが検出する「一致率」だけでは判断できない、新しいリスクへの対応が求められています。
- AI 記事の剽窃には「逐語的一致」「パラフレーズ」「モザイク型」の 3 パターンがあり、いずれもコピペチェックツールでは検出しにくい
- 著作権侵害の成立には「類似性」と「依拠性」の 2 要件が必要で、AI 利用では利用者が元ネタを知らなくても依拠性が認められ得る
- 「コピペ率○%以下なら OK」という数値基準は万能ではなく、一致の中身を確認する工程が不可欠
- 公開前に 5 ステップの体系的なチェックフローを回すことで、法的リスクと検索評価の低下を防げる
- 海外の剽窃チェックツールは日本語対応に限界があり、日本語で完結するワークフローの構築が現実的
文化庁のガイドラインでも示されている通り、AI を利用した側に責任が発生する時代です。「AI が書いた」「元ネタを知らなかった」は免責理由になりません。コピペチェックを超えた剽窃チェックの体制を、今のうちに整えておくことをお勧めします。
コピペチェックの全体像と運用フローも合わせて確認し、自社のチェック体制を見直してみてください。また、AI 記事のコンプライアンスリスクと対策では、著作権以外の法令リスクについても解説しています。
よくある質問
AIが生成した文章は、そもそも剽窃にあたるのですか?
AIが学習データに含まれる著作物を無意識に再現した場合、利用者が元ネタを知らなくても「依拠性あり」と判断される可能性があります。文化庁の考え方でも、AI 利用者の認識に関わらず類似性と依拠性の両方が認められれば著作権侵害となり得るとされています。
コピペチェックツールで一致率が何%以下なら安全ですか?
公式な基準は存在しません。一致率が低くてもパラフレーズによる構造的類似が問題になるケースがあり、逆に法令条文や固有名詞の多い記事では一致率が高くても問題ないケースがあります。数字だけでの判断は危険です。
AI記事を公開して著作権侵害になった場合、責任は誰が負いますか?
AIツールの開発元ではなく、生成物を利用・公開した企業や担当者自身が法的責任を負います。「AI が書いたから知らなかった」は免責理由になりません。
海外の剽窃チェックツールは日本語の記事にも使えますか?
英語圏向けツールは日本語の形態素解析に対応していないものが多く、精度が大きく低下します。日本語コンテンツの剽窃チェックには、日本語に対応したツールやワークフローが必要です。
AIで生成した文章に加筆修正すれば、剽窃リスクはなくなりますか?
リスクは低減しますが、AI 生成部分に既存著作物との類似が残っていればゼロにはなりません。修正の際は一致箇所の特定と、独自の分析・体験の追加が重要です。