コピペチェック、ツールだけで安心していませんか? 見落とす 3 つのパターン
この記事のポイント
コピペチェックツールはリライト・画像転用・翻訳流用の 3 パターンを見落とします。AI 生成記事は類似リスクが高く、ツール + 目視 + コンプラチェックの 3 段階フローが必要です。
コピペチェックとは、作成した文章が他のウェブサイトや文献の文章と重複していないかを検出する作業のことです。文字列の一致率を計算するツールが広く使われていますが、ツールだけでは見落とすパターンが存在します。AI で記事を量産する時代だからこそ、ツールの限界を理解し、運用でカバーする体制が求められています。
コピペチェックとは? なぜ今、改めて重要なのか
「コピペチェックはもうやっている」という企業やメディア運営者は多いでしょう。しかし、AI 生成コンテンツが当たり前になった 2026年の今、コピペチェックの意味合いそのものが変わりつつあります。
コピペチェックの基本的な仕組み
コピペチェックツールは、入力された文章を短いフレーズ(n-gram)に分割し、ウェブ上の既存コンテンツと照合します。一致するフレーズの割合を「一致率」として算出し、重複の度合いを数値化する仕組みです。
この仕組みは「文字列の一致」を検出するのが得意ですが、裏を返せば「文字列が一致しない重複」は検出できません。ここにツールの限界があります。
AI 時代に高まるコピペチェックの重要性
2024年以降、AI を使った記事生成が急速に普及しました。1 日に数十本の記事を生成する企業も珍しくありません。ところが、量産の裏側でコンテンツの類似リスクが急増しています。
Google は 2025年のヘルプフルコンテンツシステムのアップデートで、コピーコンテンツや低品質な AI 生成記事への対処を強化しました。著作権侵害のリスクだけでなく、検索順位の大幅な低下という実害が発生する時代です。「チェックしているから大丈夫」ではなく、「何を、どうチェックしているか」が問われています。
ツールが見落とす 3 つのパターン
コピペチェックツールを通して「一致率 10%」と表示されると安心しがちです。しかし、以下の 3 つのパターンはツールの検出網をすり抜けます。
パターン 1 -- リライト・パラフレーズによる構造的な類似
元の文章の語彙を入れ替え、語順を変えただけのリライトは、文字列の一致率を大幅に下げます。ツール上は「問題なし」と判定されますが、文章の構造、論旨の展開順序、具体例の選び方がそのまま残っていれば、実質的にはコピーです。
たとえば、ある記事が「原因 → 3 つの対策 → まとめ」という構成で書かれており、同じ 3 つの対策を同じ順序で同じ根拠を使って説明している記事があれば、たとえ一致率が 5% でも著作権の観点ではリスクがあります。
パターン 2 -- 画像・図表・データの無断転用
コピペチェックツールはテキストを対象としているため、画像や図表の転用は一切検出しません。他サイトのグラフをスクリーンショットで貼り付けたり、独自調査の数値をそのまま引用したりするケースは、目視でしか発見できません。
特に注意が必要なのは、統計データやアンケート結果の無断利用です。「出典を明記すれば問題ない」と思われがちですが、引用の要件(主従関係、出典明示、必然性など)を満たしていなければ著作権侵害に該当する可能性があります。
パターン 3 -- 翻訳コンテンツの流用
海外の英語記事を翻訳して日本語記事として公開するケースも、ツールは検出しにくいパターンです。言語が異なるため文字列の一致は発生しませんが、元記事の著作権は翻訳後も有効です。
Turnitin や Copyscape など海外のコピペチェックツールには多言語対応の機能がありますが、日本語の精度には限界があります。英語圏ではこうした多言語チェックが普及している一方、国内ではまだ対応が遅れているのが現状です。
翻訳元の記事が Creative Commons ライセンスであっても、ライセンスの種類によっては商用利用や改変が制限されています。ライセンス条件を必ず確認してください。
一致率の数字だけで判断していませんか? 正しい読み方
コピペチェックの結果画面で最も目につくのが「一致率」の数字です。しかし、この数字の解釈を誤ると、安全なコンテンツを不必要に修正したり、危険なコンテンツを見逃したりします。
一致率の目安 -- 30% 以下が安全圏、50% 以上は要対処
一般的に、以下の目安が使われています。
| 一致率 | 判定 | 対応 |
|---|---|---|
| 0〜15% | 安全 | そのまま公開可 |
| 16〜30% | 注意 | 一致箇所を確認し、必要に応じて修正 |
| 31〜50% | 警告 | 一致箇所の書き換えが必要 |
| 51% 以上 | 危険 | 大幅な修正または記事の作り直しが必要 |
ただし、これはあくまで目安です。一致率の数字だけでコンテンツの品質を判断するのは危険です。
一致率が低くても危険なケース(構造コピー、論旨の盗用)
一致率が 10% でも、記事全体の構成が他サイトと同一であれば問題です。見出しの順序、主張の展開、結論の導き方が酷似している「構造コピー」は、文字列の一致としては表れません。
また、他者が独自に行った分析や考察の論旨をそのまま借用する「論旨の盗用」もツールでは検出できません。学術論文の世界ではパラフレーズの盗用として厳しく取り締まられていますが、ウェブコンテンツの領域ではまだ意識が低いのが実情です。
一致率が高くても問題ないケース(固有名詞、法令文、引用)
逆に、一致率が 40% を超えていても問題ないケースもあります。
- 固有名詞や専門用語が多い記事(医療、法律、IT 分野など)
- 法令の条文を引用している記事
- 適切な引用ルールに従って他者の文章を引用している記事
- 自社の過去記事と部分的に重複している記事
こうしたケースでは、一致率の高さに慌てて表現を無理に変えると、かえって正確性が損なわれます。一致率の「内訳」を確認し、なぜ一致しているのかを判断する工程が必要です。
AI 生成記事のコピペリスク -- 従来のチェックでは足りない理由
ChatGPT や Claude などの大規模言語モデルで生成した記事には、従来のコピペチェックでは対応しきれない固有のリスクがあります。
AI が同じ情報源を参照する「収束問題」
AI は大量のウェブコンテンツを学習データとして使用しています。特定のトピックについて質問すると、学習データの中で支配的だった情報源の影響を受けた回答が生成されます。
その結果、異なるユーザーが同じテーマで AI に記事を書かせると、構成や表現が似通った記事が大量に生まれます。これが「収束問題」です。個々の記事は他サイトのコピーではありませんが、結果として似たような記事がウェブ上に溢れることになります。
Google はこうした「付加価値のない類似コンテンツ」を検索結果から排除する方針を明確にしています。コピペチェックの一致率が低くても、検索エンジンから低品質と判断される可能性があるのです。
事実の記述が似通う -- ファクトチェックとの境界線
「東京タワーの高さは 333m です」という事実の記述は誰が書いても同じになります。AI が生成する記事にはこうした事実の記述が多く含まれるため、ある程度の類似は避けられません。
問題は、事実の記述と独自の分析・考察の境界が曖昧になることです。AI は事実をベースにしつつ、学習データ中の分析パターンをなぞった「それっぽい考察」を生成します。この「それっぽい考察」が他サイトの分析と酷似していた場合、意図せず論旨の盗用に近い状態になるリスクがあります。
AI 記事に必要な品質チェックの新しい基準
AI 生成記事の品質を担保するには、従来のコピペチェックに加えて、以下の観点が必要です。
| チェック観点 | 従来のコピペチェック | AI 時代に追加で必要なチェック |
|---|---|---|
| 文字列の重複 | 対応可 | 引き続き必要 |
| 構造の類似 | 対応不可 | 目視での確認が必要 |
| 事実の正確性 | 対象外 | ファクトチェックが必須 |
| 独自性の有無 | 判定困難 | 一次情報・独自分析の追加が必要 |
| 法令遵守 | 対象外 | コンプライアンスチェックが必要 |
AI が生成した記事をそのまま公開するのではなく、人間が独自の視点や体験を加えて「自社だけの記事」に仕上げる工程が欠かせません。
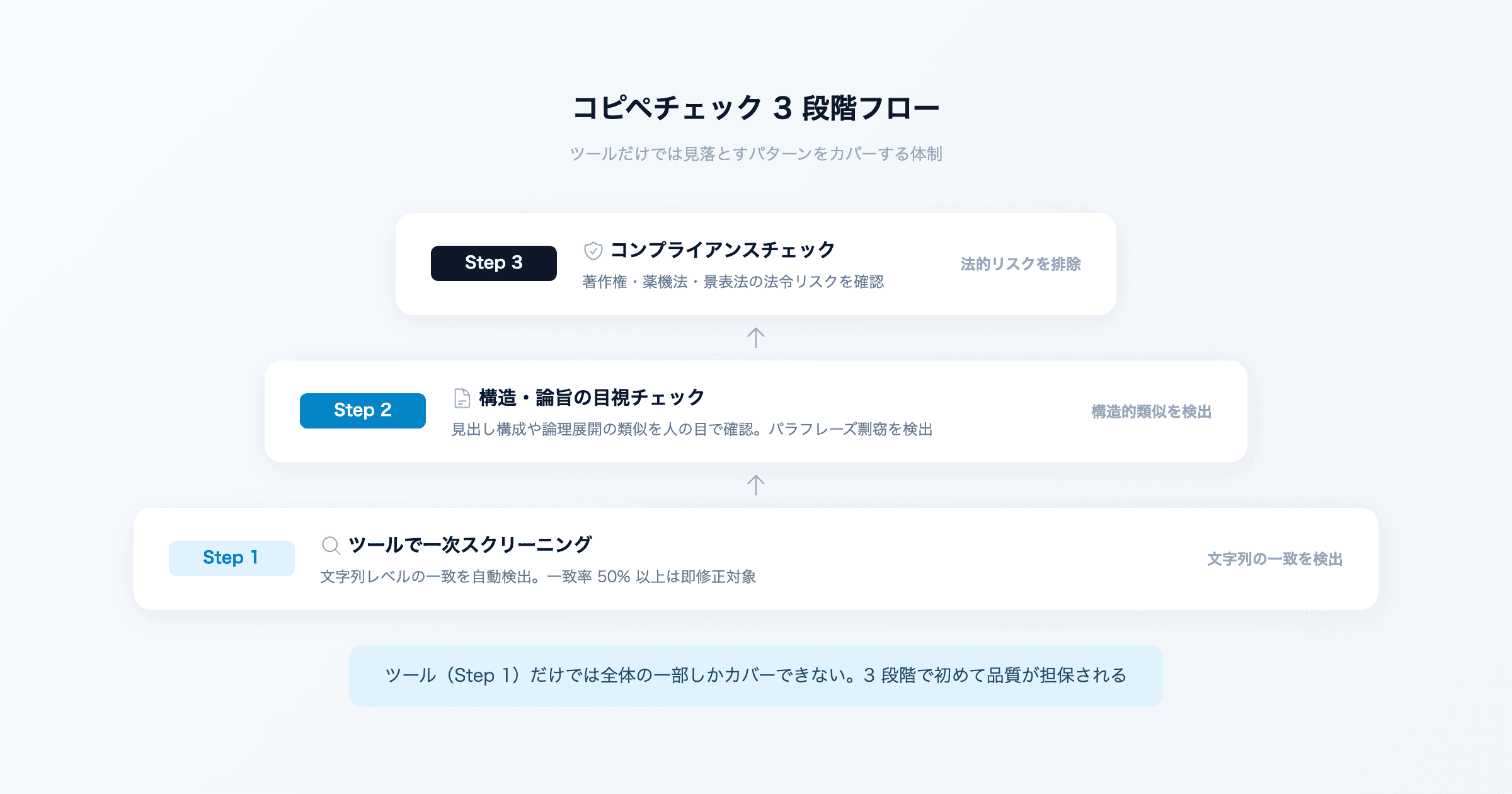
ツール + 人の目 + 仕組みで守る -- 実践的なチェックフロー
ツールの限界を理解した上で、実際にどのような手順でチェックすればよいのか。3 つのステップで構成されるチェックフローを紹介します。
ステップ 1 -- ツールで一次スクリーニング
最初のステップは、コピペチェックツールによる一次スクリーニングです。ここでは文字列レベルの重複を検出し、明らかなコピーを除外します。
一致率が 30% を超えた箇所は個別に確認し、固有名詞や引用による一致なのか、実質的なコピーなのかを切り分けます。この段階で問題なければ次のステップへ進みます。
海外では Turnitin(主に学術分野)や Copyscape(ウェブコンテンツ向け)が広く使われていますが、いずれも日本語の対応は限定的です。日本語コンテンツの場合、ツールによる一次スクリーニングだけでは不十分なケースが多く、次のステップがより重要になります。
ステップ 2 -- 構造・論旨レベルの目視チェック
ツールでは検出できない構造的な類似や論旨の盗用を、人の目で確認するステップです。具体的には以下のポイントを確認します。
- 見出し構成が他サイトと同一になっていないか
- 論旨の展開順序が特定の記事と酷似していないか
- 使用している具体例やデータの出典が適切か
- 画像・図表が他サイトからの無断転用でないか
- 翻訳元の記事が存在しないか
特に AI で生成した記事は、同じテーマの上位記事と構成が似通いやすい傾向があります。検索上位 3〜5 記事の見出し構成と見比べて、差別化ポイントがあるかを確認することが重要です。
ステップ 3 -- コンプライアンス観点のチェック(著作権・薬機法・景表法)
コピペチェックと混同されがちですが、コンプライアンスチェックは別の工程です。著作権の問題だけでなく、薬機法(健康食品や化粧品の効能表現)、景表法(不当な優良表示や有利表示)、特定商取引法などの法令に違反する表現がないかを確認します。
AI が生成した文章には、事実と異なる効能表現や根拠のない比較表現が含まれることがあります。こうした表現は、コピペチェックの対象外ですが、法的リスクは極めて高いものです。
AI で作った記事のコンプライアンスリスクと対策で詳しく解説していますが、AI 記事のリスクは「コピー」だけではありません。法令違反のリスクも同時にチェックする体制が必要です。
spotyou のコンプライアンスチェック機能では、薬機法・景表法・著作権の観点から AI 生成記事を自動スキャンし、リスクのある表現を指摘します。ツールでのコピペチェックとコンプライアンスチェックを一つのワークフロー内で完結できます。
チェックを属人化させない仕組みづくり
チェックの品質を維持するには、担当者の経験や勘に頼らない仕組みが必要です。
- チェックリストを作成し、ステップ 1〜3 の各項目を明文化する
- 記事公開前のレビューフローを定義し、チェック完了を公開の必須条件にする
- チェック結果を記録し、過去に指摘が多かったパターンをナレッジとして蓄積する
特にチームで記事を量産している場合、担当者ごとにチェックの精度にばらつきが出やすくなります。ツールで自動化できる部分は自動化し、人が判断すべき部分を明確にすることで、属人化を防げます。
spotyou で実際に記事を作る全工程では、キーワード選定からコンプライアンスチェックまでの一連のフローを公開しています。チェック体制の構築に悩んでいる方は参考にしてみてください。
まとめ: コピペチェックはツールと運用の両輪で
コピペチェックは「ツールを通せば終わり」ではなく、ツールの限界を理解した上で運用でカバーする体制が必要です。
- コピペチェックツールは文字列の一致しか検出できない。リライト、画像転用、翻訳流用の 3 パターンはツールの検出網をすり抜ける
- 一致率の数字だけで判断せず、一致の「内訳」と「構造的な類似」を人の目で確認する
- AI 生成記事は収束問題により類似リスクが高く、独自性の追加とファクトチェックが必須
- ツールによる一次スクリーニング、目視での構造チェック、コンプライアンスチェックの 3 段階フローで運用する
- チェックを属人化させず、チェックリストとレビューフローで仕組み化する
AI を活用した記事制作が当たり前になる中で、コピペチェックの定義そのものが拡張されています。文字列の重複だけでなく、構造の類似、法令遵守、独自性の確保まで含めた「品質チェック」として捉え直すことが、これからのコンテンツ運用には求められています。
よくある質問
コピペチェックの一致率はどのくらいなら安全ですか?
一般的には 30% 以下が安全圏とされています。ただし一致率が低くても、文章構造や論旨が他サイトと酷似している場合は注意が必要です。
AI(ChatGPT 等)で生成した記事もコピペチェックは必要ですか?
はい、むしろ従来以上に重要です。AI は学習データに基づいて文章を生成するため、他サイトと表現や構造が似通うリスクがあります。
コピペチェックツールで検出できないケースはありますか?
はい。リライト、画像・図表の無断転用、海外記事の翻訳流用などはツールが検出しにくいパターンです。
コピペが発覚した場合、SEO にどのような影響がありますか?
Google はコピーコンテンツを低品質と判断し、検索順位の大幅な低下やインデックスからの除外といったペナルティを科す場合があります。
コピペチェックとコンプライアンスチェックは何が違いますか?
コピペチェックは他者の文章との重複を検出するもの、コンプライアンスチェックは薬機法・景表法などの法令違反がないかを確認するものです。AI 生成記事では両方のチェックが必要です。